堆基础知识
导语
入门堆溢出之前,首先要对堆有个基础的了解
堆的简单介绍
可能经常听到这个说法,栈内存由os操作,堆地址由程序员操作。这个说法有一定的可取之处。
堆管理器处于用户程序与内核中间,主要做以下工作
- 响应用户的申请内存请求,向操作系统申请内存,然后将其返回给用户程序。同时,为了保持内存管理的高效性,内核一般都会预先分配很大的一块连续的内存,然后让堆管理器通过某种算法管理这块内存。只有当出现了堆空间不足的情况,堆管理器才会再次与操作系统进行交互。
- 管理用户所释放的内存。一般来说,用户释放的内存并不是直接返还给操作系统的,而是由堆管理器进行管理。这些释放的内存可以来响应用户新申请的内存的请求。
Linux 中早期的堆分配与回收由 Doug Lea 实现,但是多线程共享堆的内存空间,在申请的时候需要加锁,这就导致了多线程对堆的操作效率很低。在glibc-2.3.x只有,目前的堆由ptmalloc2管理。
需要注意的是,在内存分配与使用的过程中,Linux 有这样的一个基本内存管理思想, 只有当真正访问一个地址的时候,系统才会建立虚拟页面与物理页面的映射关系 。 所以虽然操作系统已经给程序分配了很大的一块内存,但是这块内存其实只是虚拟内存。只有当用户使用到相应的内存时,系统才会真正分配物理页面给用户使用。
程序的内存结构
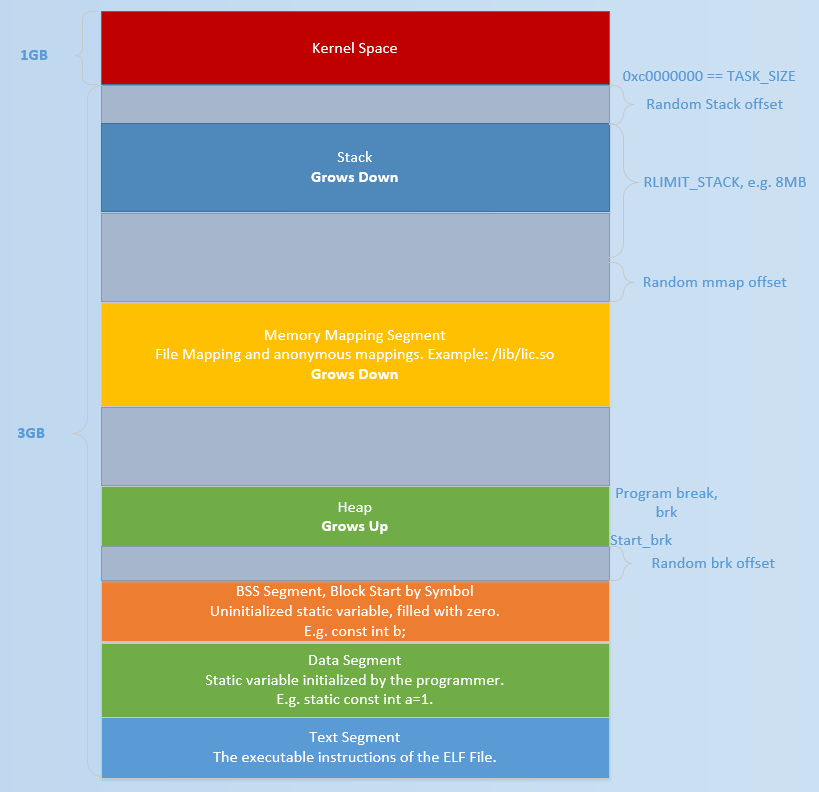
一段代码的内存都有bss段、text段和data段
text段 程序代码段,通常只读
data段 从stack一直到heap都是data段
bss段 Block Started by Symbol,定义而没有赋初值的全局变量和静态变量,放在这个区域,通常只是记录变量名和大小,相当于一个占位符。
data段里又包括栈、堆和文件映射区域
stack和heap是两头往中间着增长的,stack往地地址长,heap往高地址长。
从操作系统角度来看,进程分配内存有两种方式,分别由两个系统调用完成:brk和mmap(不考虑共享内存)。
brk是改变program break,来增加heap的大小
mmap是在进程的虚拟地址空间中(文件映射区域)找一块空闲的虚拟内存进行映射
注意,我们在上文中提到过,在访问地址之前,虚拟地址与物理地址的映射是未被建立的,因此这两种方式分配的都是虚拟内存,没有分配物理内存,会在第一次访问的时候通过缺页中断建立虚拟地址和物理地址的映射。
这个《深入理解计算机系统》的图不错,但是.rodata .init在网上图里都不是很常见
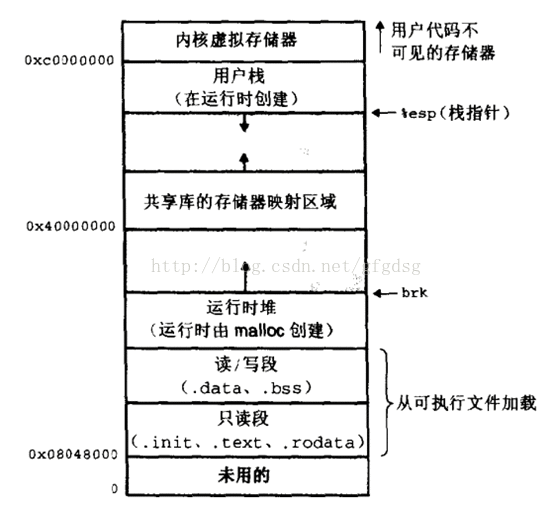
1、只读段:该部分空间只能读,不可写;(包括:代码段、rodata 段(C常量字符串和#define定义的常量) )
2、数据段:保存全局变量、静态变量的空间;
3、堆 :就是平时所说的动态内存, malloc/new 大部分都来源于此。其中堆顶的位置可通过函数 brk 和 sbrk 进行动态调整。
4、文件映射区域 :如动态库、共享内存等映射物理空间的内存,一般是 mmap 函数所分配的虚拟地址空间。
5、栈:用于维护函数调用的上下文空间,一般为 8M ,可通过 ulimit –s 查看。
6、内核虚拟空间:用户代码不可见的内存区域,由内核管理(页表就存放在内核虚拟空间)。
内存申请的多线程支持
在之前的dlmalloc由于内存是临界资源,所以有上锁的问题导致效率较差,咱们ptmaloc2的解决办法是线程共享多个堆,即临界资源数量变多了。
https://ctf-wiki.org/pwn/linux/user-mode/heap/ptmalloc2/heap-overview/#_5
虽然程序可能只是向操作系统申请很小的内存,但是为了方便,操作系统会把很大的内存分配给程序。这样的话,就避免了多次内核态与用户态的切换,提高了程序的效率。
这些被分配的内存被称为arena,主线程申请的内存为 main_arena,在子线程申请内存的时候会出现子arena
chunk
在程序的执行过程中,我们称由 malloc 申请的内存为 chunk 。这块内存在 ptmalloc 内部用 malloc_chunk 结构体来表示。当程序申请的 chunk 被 free 后,会被加入到相应的空闲管理列表中。
malloc_chunk 的结构如下
/* |
其中INTERNAL_SIZE_T的定义如下
/* INTERNAL_SIZE_T is the word-size used for internal bookkeeping of |
size_t 在 64 位中是 64 位无符号整数,32 位中是 32 位无符号整数
其他字段的含义如下
prev_size , 如果该 chunk 的 物理相邻的前一地址 chunk(两个指针的地址差值为前一 chunk 大小) 是空闲的话,那该字段记录的是前一个 chunk 的大小 (包括 chunk 头)。否则,该字段可以用来存储前一个 chunk 的数据。 *这里的前一 chunk 指的是较低地址的 chunk * 。(一个word都锱铢必较,这就是硬件层程序员的实力吗 跪)
size ,该 chunk 的大小,单位是字节,需要注意的是大小必须是 2 * SIZE_SZ 的整数倍。如果申请的内存大小不是 2 * SIZE_SZ 的整数倍,会被转换满足大小的最小的 2 * SIZE_SZ 的倍数。32 位系统中,SIZE_SZ 是 4;64 位系统中,SIZE_SZ 是 8。 该字段的低三个比特位对 chunk 的大小没有影响,它们从高到低分别表示
- NON_MAIN_ARENA,记录当前 chunk 是否不属于主线程,1 表示不属于,0 表示属于。
- IS_MAPPED,记录当前 chunk 是否是由 mmap 分配的。
- PREV_INUSE,记录前一个 chunk 块是否被分配。一般来说,堆中第一个被分配的内存块的 size 字段的 P 位都会被设置为 1,以便于防止访问前面的非法内存。当一个 chunk 的 size 的 P 位为 0 时,我们能通过 prev_size 字段来获取上一个 chunk 的大小以及地址。这也方便进行空闲 chunk 之间的合并。
请注意,这个字段的最低3位用于存储其他信息,因此实际的chunk大小应该是size字段值与0xFFFFFFF8按位与的结果。也就因此最小的chunk至少也该是0b1000=8个字节。size域的大小为字长,即32位程序的size域大小为32位,64位程序的size域大小为64位。
fd,bk 。 chunk 处于分配状态时,从 fd 字段开始是用户的数据。chunk 空闲时,会被添加到对应的空闲管理链表中,其字段的含义如下
- fd 指向下一个(非物理相邻)空闲的 chunk
- bk 指向上一个(非物理相邻)空闲的 chunk
- 通过 fd 和 bk 可以将空闲的 chunk 块加入到空闲的 chunk 块链表进行统一管理
只有当chunk是free时,ptmalloc才会给chunk加上fd和bk指针,在chunk不free的时候,这两个字长的内存被user data使用。
fd_nextsize, bk_nextsize ,也是只有 chunk 空闲的时候才使用,不过其用于较大的 chunk(large chunk)。
- fd_nextsize 指向前一个与当前 chunk 大小不同的第一个空闲块,不包含 bin 的头指针。
- bk_nextsize 指向后一个与当前 chunk 大小不同的第一个空闲块,不包含 bin 的头指针。
- 一般空闲的 large chunk 在 fd 的遍历顺序中,按照由大到小的顺序排列。这样做可以避免在寻找合适 chunk 时挨个遍历。
大概是长这样
chunk-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ |
称Size of previous chunk, if unallocated和Size of chunk, in bytes为chunk header,后面的成为userdata
被释放的chunk以链表形式存储,在内存里的形式是这样的
chunk-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ |
一般情况下 ,物理相邻的两个空闲 chunk 会被合并为一个 chunk 。堆管理器会通过 prev_size 字段以及 size 字段合并两个物理相邻的空闲 chunk 块。
做个实验
|
在exit前下断点,查看堆
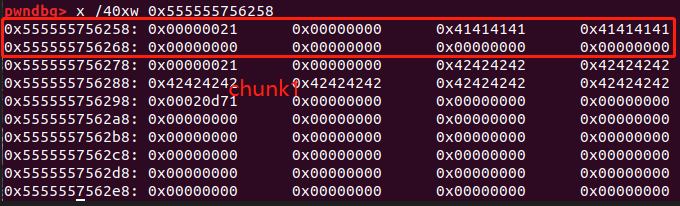
可以看到chunk1的结构是
size域 0x00000000 00000021,根据size域的结构,chunk的大小应该是32字节
userdata域 0x41414141 41414141 00000000 00000000 00000000 00000000根据size对齐chunk应该是16对齐,因此这个chunk被多填充了
类似的,32位如下

0x11=0b1 0001,大小为16字节
在最后的0x21e79应该是这个arena或者bin剩余的可用空间(但是我不是很确定)

因为当我在多malloc几个字节,导致第二个chunk长了0x20的情况下,这个值会减少0x20
bin
我们曾经说过,用户释放掉的 chunk 不会马上归还给系统,ptmalloc 会统一管理 heap 和 mmap 映射区域中的空闲的 chunk。当用户再一次请求分配内存时,ptmalloc 分配器会试图在空闲的 chunk 中挑选一块合适的给用户。这样可以避免频繁的系统调用,降低内存分配的开销。
在具体的实现中,ptmalloc 采用分箱式方法对空闲的 chunk 进行管理。首先,它会根据空闲的 chunk 的大小以及使用状态将 chunk 初步分为 4 类:fast bins,small bins,large bins,unsorted bin。每类中仍然有更细的划分,fast bins以单链表连接来满足fast bins的效率需求,而其他的bins中的 chunk 会用双向链表链接起来。
对于small bins,large bins,unsorted bins 来说,ptmalloc 将它们维护在同一个数组bins array中。数组内存着mchunkptr指针,相当于一个头指针,指向一个由被free的chunk构成的链表
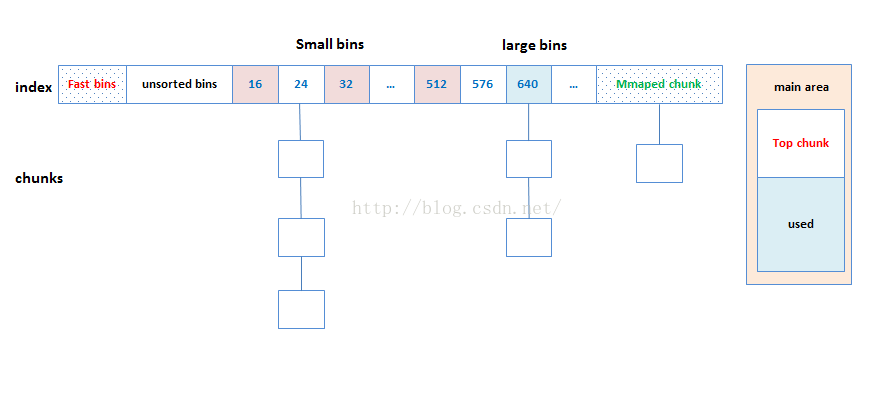
上图可能有点误导,fast bin不在bins array中,bins array共维护128个bin的结构如下
- unsorted bin (bins array[0]),
- small bins (bins array[1] to bins array[62]),
- large bins (bins array[63] to bins array[126])
- unsorted bin again (bins array[127])
下面我们来细说一下不同的bins。
- fast bins 。fast bins是bins的高速缓冲区,以单链表形式存在,大约有10个定长队列。当用户释放一块不大于max_fast(默认值64)的chunk(一般小内存)的时候,会默认会被放到fast bins上。当用户下次需要申请内存的时候首先会到fast bins上寻找是否有合适的chunk,然后才会到bins上空闲的chunk。ptmalloc会遍历fast bin,看是否有合适的chunk需要合并到bins上。为了更符合局部性原理,fast bins会采用LIFO的管理策略。
- unsorted bins 。只有一个链表,是bins的一个缓冲区。当用户释放的内存大于max_fast或者fast bins合并后的chunk都会进入unsorted bin上。当用户malloc的时候,先会到unsorted bin上查找是否有合适的bin,如果没有合适的bin,ptmalloc会将unsorted bin上的chunk放入合适的bins上,然后再到bins上查找合适的空闲chunk。unsorted bins采取FIFO的管理策略
- small bins和large bins 。small bins和large bins是真正用来放置chunk双向链表的。每个bin之间相差8个字节,并且通过上面的这个列表,可以快速定位到合适大小的空闲chunk。前64个为small bins,定长;后64个为large bins,非定长。
- Top chunk 。并不是所有的chunk都会被放到bins上。top chunk相当于分配区的顶部空闲内存,当bins上都不能满足内存分配要求的时候,就会来top chunk上分配。
- mmaped chunk。 当分配的内存非常大(大于分配阀值,默认128K)的时候,需要被mmap映射,则会放到mmaped chunk上,当释放mmaped chunk上的内存的时候会直接交还给操作系统。
fast bins和unsorted bins链表中的chunk没有大小顺序,small bins和large bins中,每个bin里存放固定大小的chunk。
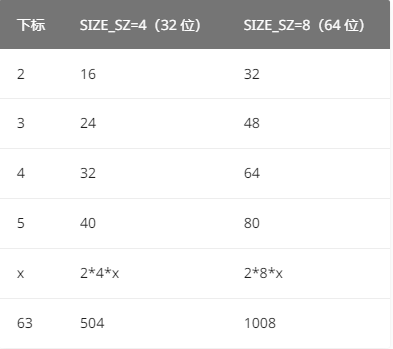
small bins的62个bins之间有固定的公差,如下图
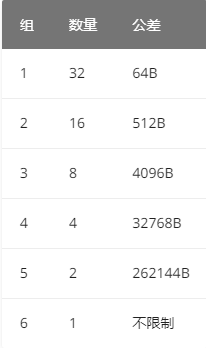
large bins的64个bins被分为了6组,不同组内的公差不一样大,如下图
在分配内存时,ptmalloc2会以这样的优先级顺序来寻找chunk:
- fast bins (LIFO)
- unsorted bins (FIFO)
- small bins & large bins
arena
之前我们介绍过,ptmalloc为了实现多线程,使用了arena,无论是主线程还是新创建的线程,在第一次申请内存时,都会有独立的 arena。但是arena也有数量限制,在32位系统中,arena的数量为处理器核心数的2倍,64位系统中则为核心数的8倍。
一个arena里的结构大概是这样了
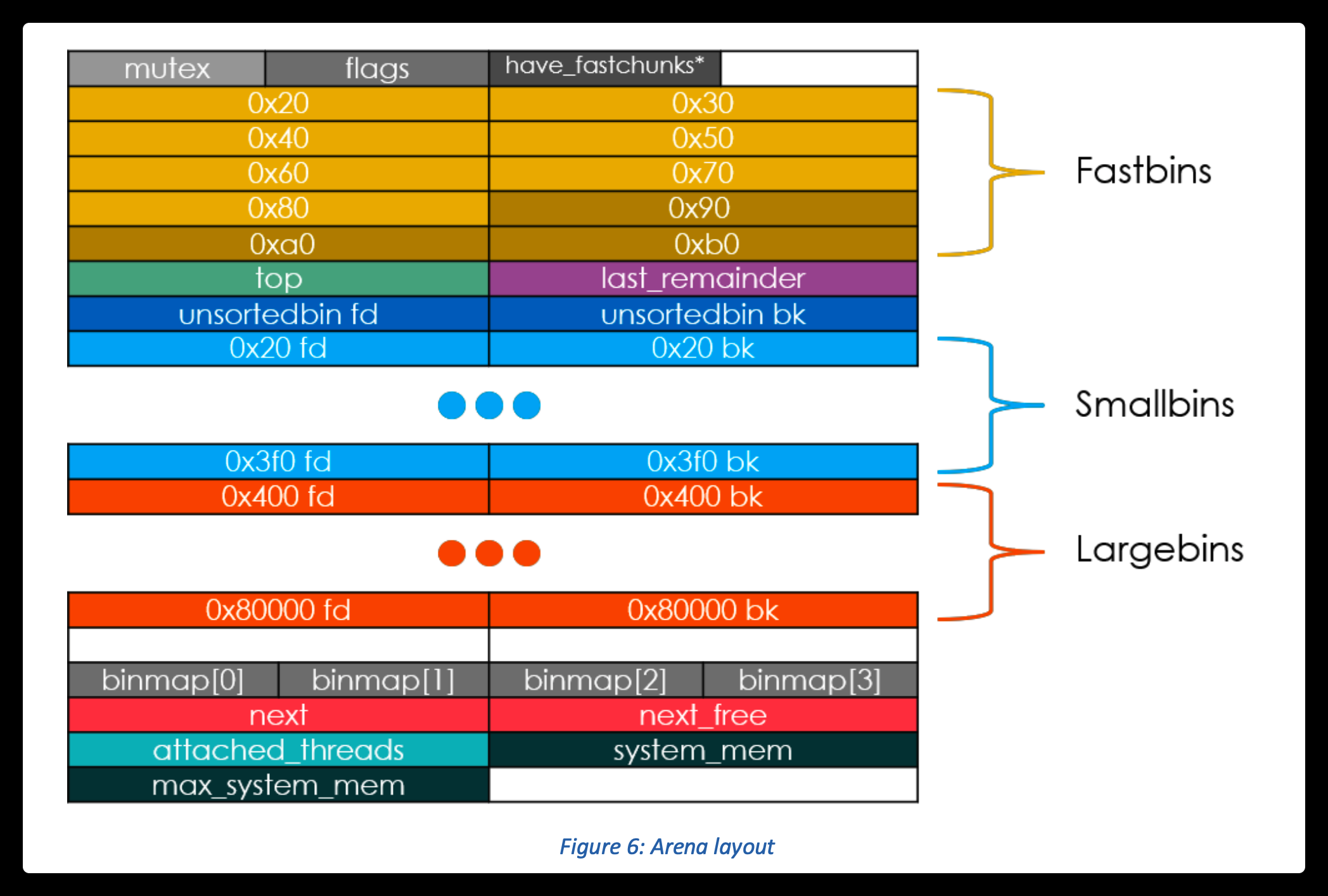
还有一个 Top Chunk
程序第一次进行 malloc 的时候,heap 会被分为两块,一块给用户,剩下的那块就是 top chunk。其实,所谓的 top chunk 就是处于当前堆的物理地址最高的 chunk。这个 chunk 不属于任何一个 bin,它的作用在于当所有的 bin 都无法满足用户请求的大小时,如果其大小不小于指定的大小,就进行分配,并将剩下的部分作为新的 top chunk。否则,就对 heap 进行扩展后再进行分配。在 main arena 中通过 sbrk 扩展 heap,而在 thread arena 中通过 mmap 分配新的 heap。
至此,我们已经可以宏观的看待ptmalloc2堆内存分配了:
线程与arena对应,每个arena中含有多个bins,每个bin里存放着一个个的chunk,chunk是malloc的单位
参考:
 wechat
wechat alipay
alipay


