面试押题
导语
冲一波春招吧,希望能得偿所愿!找了找别人的面经,押个题先!
堆和栈的区别
| 堆 | 栈 |
|---|---|
| 一般由程序员分配释放, 若程序员不释放,程序结束时可能由OS回收 | 由操作系统(编译器)自动分配释放 |
| 堆是由new分配的内存,一般速度比较慢,而且容易产生内存碎片 | 栈由系统自动分配,速度较快 |
| 分配方式类似于链表 | 操作方式类似于数据结构中的栈 |
| 存放使用new创建的对象,全局变量 | 存放基本数据类型的变量数据 和 对象的引用,局部变量 |
| 首先应该知道操作系统有一个记录空闲内存地址的链表,当系统收到程序的申请时,会遍历该链表,寻找第一个空间大于所申请空间的堆结点,然后将该结点从空闲结点链表中删除,并将该结点的空间分配给程序 | 只要栈的剩余空间大于所申请空间,系统将为程序提供内存,否则将报异常提示栈溢出。 |
| 在Windows下,栈是向低地址扩展的数据结构,是一块连续的内存的区域。这句话的意思是栈顶的地址和栈的最 大容量是系统预先规定好的,如果申请的空间超过栈的剩余空间时, 将提示overflow | 堆是向高地址扩展的数据结构,是不连续的内存区域,堆的大小受限于计算机系统中有效的虚拟内存。 |
一般认为在c中分为这几个存储区
1栈 - 由编译器自动分配释放
2堆 - 一般由程序员分配释放,若程序员不释放,程序结束时可能由OS回收
3全局区(静态区),全局变量和静态变量的存储是放在一块的,初始化的全局变量和静态变量在一块区域,未初始化的全局变量和未初始化的静态变量在相邻的另一块区域。 程序结束释放。
4另外还有一个专门放常量的地方。 - 程序结束释放
在函数体中定义的变量通常是在栈上,用malloc, calloc, realloc等分配内存的函数分配得到的就是在堆上。在所有函数体外定义的是全局量,加了static修饰符后不管在哪里都存放在全局区(静态区),在所有函数体外定义的static变量表示在该文件中有效,不能extern到别的文件用,在函数体内定义的static表示只在该函数体内有效。
壳 加壳 脱壳
“壳”是一段先丁被保护的程序运行的一段程序,它们附加在原程序上通过Windows加载器载入内存后,先于原始程序执行,得到控制权,执行过程中对原始程序进行解密,还原,还原完成后再把控制权交还给原始程序,执行原来的代码部分’
根据实现的功能。
从某种意义上来说,某些木马病毒也是实现了相似的功能,即修改入口点然后在执行完了功能后在到原本程序的入口点。
脱壳方法有两种
第一种是硬脱壳,这是指找出加壳软件的加壳算法,写出逆向算法,就像压缩和解压缩一样。由于,目前很多“壳”均带有加密、变形的特点,每次加壳生成的代码都不一样。硬脱壳对此无能为力,但由于其技术门槛较低,仍然被一些杀毒软件所使用。
第二种是动态脱壳。由于加壳的程序运行时必须还原成原始形态,即加壳程序会在运行时自行脱掉“马甲”。目前,有一种脱壳方式是抓取(Dump)内存中的镜像,再重构成标准的执行文件。相比硬脱壳方法,这种脱壳方法对自行加密、变形的壳处理效果更好。
常见的加密壳有UPX、ASPACK等
堆栈平衡
堆栈平衡就是call完了之后ret时sp要指向call之前的下一条指令。
在call时会先将当前的ip内容(或者说下一条要执行的指令的地址)压栈,如果堆栈不平衡,ret的时候会pop ip,这就导致程序去了奇怪的地方执行奇怪的代码(或许连代码都8是,但是被硬当做代码了)。一般情况下的堆栈平衡主要是整sp和bp这两个确定堆栈的指针。在call一个函数的时候,调用者首先把参数压入堆栈,然后调用子程序,在完成后,由于堆栈中先前压入的数不再有用,调用者或者被调用者必须有一方把堆栈指针修正到调用前的状态。假如我调用了一个add(int a, intb)有2个参数,在call之前就会push a和push b 因此需要给sp增加0x8才能保证堆栈平衡,这个add sp 0x8的操作一般在经过编译的函数里实现,如果直接手撸汇编则需要手写add sp 0x8才行,只有堆栈平衡了,这个call不会发生奇怪的事情。
简述恶意代码分析
首先用在线沙箱确定确实是一个恶意程序。
恶意代码分析分为静态分析和动态分析两个步骤。
静态分析主要先查看其输入函数,以初步判断恶意代码实现了那些恶意功能,比如kernel32.dll的CreateFileA函数等可以断定他有创建文件,advapi32.dll中的注册表相关操作的api和密码相关的api等等。然后对恶意软件进行反编译,根据反编译的结果验证猜想、判断恶意行为。
动态分析是指在虚拟机中,开启监视行为的程序,比如process monitor,直接运行恶意代码,监测行为进而确定恶意代码。
常见加密算法
对称:
DES(Data Encryption Standard):,数据加密标准,速度较快,适用于加密大量数据的场合,分组密码,S盒;
3DES(Triple DES):是基于DES的对称算法,对一块数据用三个不同的密钥进行三次加密,强度更高;
RC2和RC4:,用变长密钥对大量数据进行加密,比 DES 快,分组密码,S盒;
IDEA(International Data Encryption Algorithm)国际数据加密算法,使用 128 位密钥提供非常强的安全性,分组密码;
AES(Advanced Encryption Standard):高级加密标准,速度快,安全级别高,分组密码;
BLOWFISH,它使用变长的密钥,长度可达448位,运行速度很快,分组密码;
非对称:
RSA:支持变长密钥的公共密钥算法,需要加密的文件块的长度也是可变的;
ECC(Elliptic Curves Cryptography):椭圆曲线密码编码学。
TEA(Tiny Encryption Algorithm)简单高效的加密算法,加密解密速度快,实现简单。但安全性不如DES,QQ一直用tea加密,分组密码
DSA: 用于数字签名
摘要:
MD5 SHA-1
公钥密码体制根据其所依据的难题一般分为三类:大素数分解问题类、离散对数问题类、椭圆曲线类。
国密对标
SM2 椭圆曲线
SM4≈DES
SM3 摘要算法
密钥协商
“密钥协商机制”是:(在身份认证的前提下)规避【偷窥】的风险。通俗地说,即使有攻击者在偷窥客户端与服务器的网络传输,客户端(client)依然可以利用“密钥协商机制”与服务器端(server)协商出一个只有二者可知的用来对于应用层数据进行加密的密钥(也称“会话密钥”)。
1,依靠非对称加密算法
拿到公钥的一方先生成随机的会话密钥,然后利用公钥加密它,再把加密结果发给对方,对方用私钥解密;于是双方都得到了会话密钥。
如 RSA SM2
2,依靠专门的密钥交换算法
DH算法:
依据:大素数分解的困难性
双方约定两个素数:模数p和生成元g
双方各选一个秘密的自然数(a,b),然后计算 $A=g^a mod p$ 和 $B=g^b mod p$作为双方的公钥
拿到公钥的另一方计算 $k=A^b mod g$ 和 $k=B^a mod g$ 即得到密钥
此算法不支持认证,虽然可以抵抗偷窥但是无法抵抗篡改,无法对抗中间人攻击。一般此算法会配合其余的签名算法搭配使用,比如RSA、DSA算法。
3,依靠通讯双方事先已经共享的“秘密”
即双方在此次密钥协商之前已经共享了某些秘密,只需在这个秘密的基础上进行某种生产算法即可。
https
https的加密部分是SSL安全套接字协议/TLS安全传输层协议实现的,他们在应用层和传输层之间,即在会话层和表示层
ssl的密钥协商过程如下图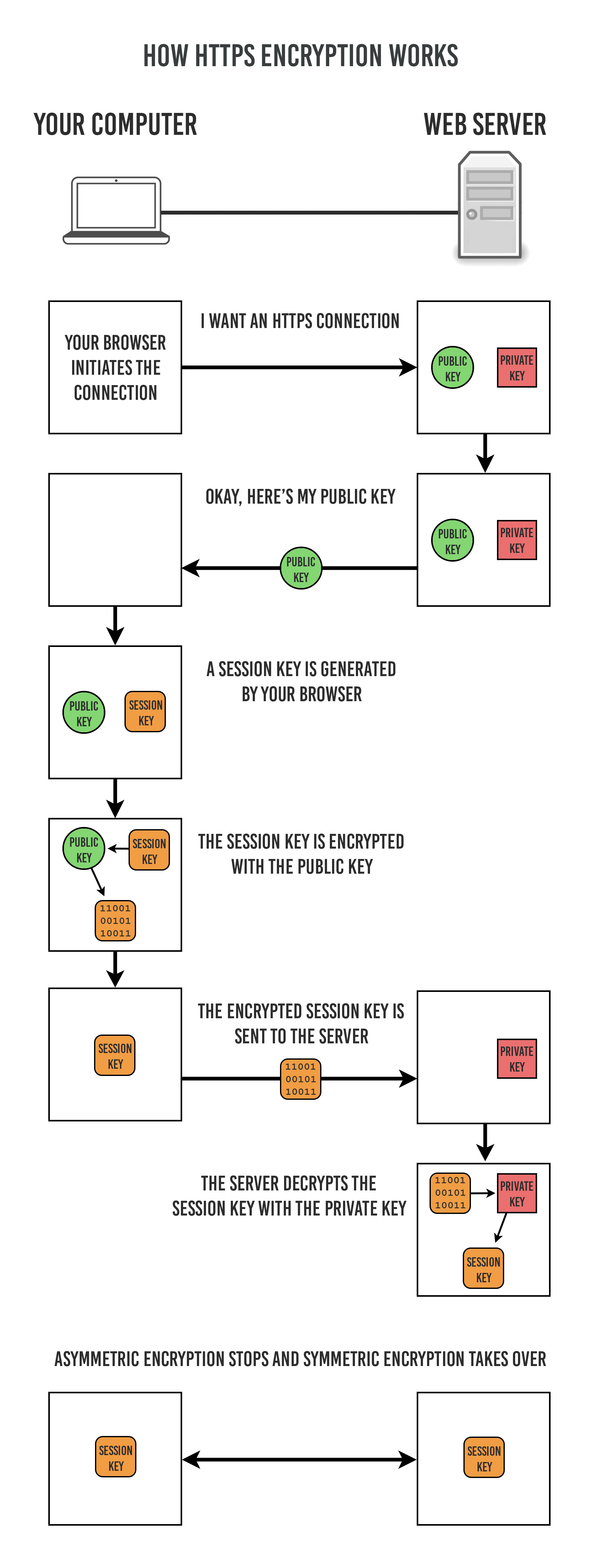
服务端提供证书供客户端验证
服务端提供公钥
客户端想一个key,用公钥加密,发给服务端
服务端用自己的私钥解密,得到key
双方使用key来对称加密。
https的证书验证机制
如下图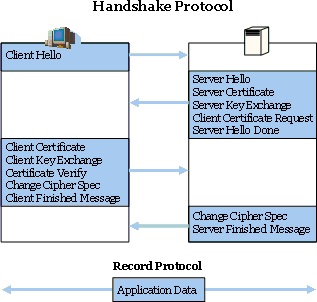
客户端证书其实平时不是很常见,需要验证客户身份的地方也不是很多,主要的例子就是银行的U盾。
简化一点的可以如下图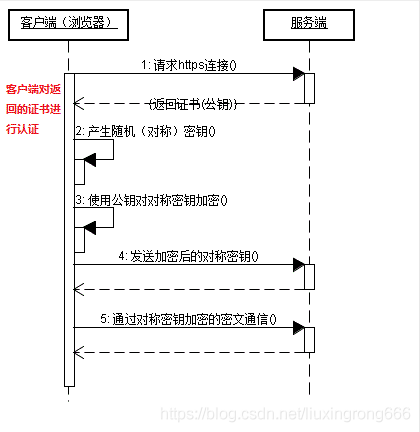
内存保护
GS
启用GS选项之后,会在函数执行一开始先往栈上保存一个数据,等函数返回时候检查这个数据,若不一致则为被覆盖,这样就跳转进入相应的处理过程,不再返回,因此shellcode也就无法被执行,这个值被称为“Security cookie”。
可是他们忽略了异常处理SEH链也在栈上因此可以覆盖SEH链为jmp esp的地址,之后触发异常跳转到esp执行shellcode。
SafeSEH
SafeSEH会将所有异常处理函数地址提取出来,编入 SEH 表中,并将这张表放到程序的映像里。异常调用时,就与这张预先存好的表中的地址进行校验。
绕过:
利用堆地址覆盖SEH结构绕过SafeSEH:在禁用DEP的进程中,异常分发器允许SEH handler位于除栈空间之外的非映像页面。也就是说我们可以把shellcode放置在堆中,然后通过覆盖SEH跳至堆空间以执行shellcode,这样即可绕过SafeSEH保护。
利用没有启用SafeSEH保护的模块绕过SafeSEH:老版本的操作系统的系统模块、旧编译器的dll文件可能没有启用SafeSEH,可以用来绕过
利用加载模块之外的地址绕过SafeSEH:对于加载模块之外的地址,SafeSEH同样是不进行有效性检测的
DEP data execution prevent
数据执行保护(DEP)指的是堆和栈只有读写权限没有执行权限。
绕过:如果程序用了kernel32.dll的VirtualProtect函数,则可以改变堆栈段的执行权限
或者使用ROP(面对return的编程),在程序可执行段收集类似于
pop eax |
这样的一个操作+ret的段,这样就可以在堆栈段控制住ip的执行。
一般都用插件,比如mona、ropme等(主要手做太麻烦了)
ASLR(Address space layout randomization)
ASLR地址空间布局随机化是让exe、dll的地址全都随机,这样就可以抵抗DEP。
对抗ASLR的方式是暴力把程序空间占满,全铺上shellcode,只要跳转地址没落在已有模块中,落在我们的空间中即可以执行了shellcode。这种将程序空间全部占满铺上shellcode的技术被称为堆喷射技术,缺无法对抗ASLR+DEP的双重防护。
Control Flow Guard(CFG)——控制流防护
CFG通过在间接跳转(Indirect Call)前插入校验代码(比如 call dword ptr ss:[ebp-8] 等等 ),检查目标地址的有效性,进而可以阻止执行流跳转到预期之外的地点, 最终及时并有效的进行异常处理,避免引发相关的安全问题。
CANNARY(栈溢出保护)
linux下的GS
启用栈保护后,函数开始执行的时候会先往栈里插入cookie信息,当函数真正返回的时候会验证cookie信息是否合法,如果不合法就停止程序运行。攻击者在覆盖返回地址的时候往往也会将cookie信息给覆盖掉,导致栈保护检查失败而阻止shellcode的执行。在Linux中我们将cookie信息称为canary。
FORTIFY
gcc生成了一些附加代码,通过对数组大小的判断替换strcpy, memcpy, memset等函数名,达到防止缓冲区溢出的作用。
NX No-eXecute
linux下的DEP
ret2libc=ROP
PIE
linux下的NX+ASLR
RELRO read only relocation
GCC, GNU linker以及Glibc-dynamic linker一起配合实现了一种叫做relro的技术: read only relocation.大概实现就是由linker指定binary的一块经过dynamic linker处理过 relocation之后的区域为只读.
RELRO设置符号重定向表格为只读或在程序启动时就解析并绑定所有动态符号,从而减少对GOT(Global Offset Table)攻击。
用于伪造的HTTP头
Referer 告诉服务器该页面从哪个页面链接的(ssrf)
X-forward-for 用来表示 HTTP 请求端真实 IP(如果有代理就挨个往后写),可以用于伪造ip(Remote address无法伪造)
User-agent 向服务器发送浏览器的版本、系统、应用程序的信息
ssrf
SSRF漏洞就是通过篡改获取资源的请求发送给服务器,但是服务器并没有检测这个请求是否合法的,然后服务器以他的身份来访问其他服务器的资源。
ssrf可以做到
1.内外网的端口和服务扫描
2.主机本地敏感数据的读取
3.内外网主机应用程序漏洞的利用
4.内外网Web站点漏洞的利用
例子
1、利用file协议读取文件
2、利用dict协议查看端口开放
3、利用gopher协议反弹shell
造成原因
1、curl
2、file_get_contents
3、fsockopen
修复方案:
限制协议为HTTP、HTTPS
不用限制302重定向
设置URL白名单或者限制内网IP
csrf cross-site request forgery 跨站脚本伪造
攻击者盗用了你的身份,以你的名义发送恶意请求。
比如你在A站生成了一个cookie,然后你访问了B站,B站让你往A站发请求,而浏览器会自己读取cookie,A站就以为是你本人发的
CSRF能够做的事情包括:以你名义发送邮件,发消息,盗取你的账号,甚至于购买商品,虚拟货币转账等
造成的问题包括:个人隐私泄露以及财产安全。
要完成一次CSRF攻击,受害者必须依次完成两个步骤:
1.登录受信任网站A,并在本地生成Cookie。
2.在不登出A的情况下,访问危险网站B。
例子:
1、在危险B站有一个<img src=http://www.mybank.com/Transfer.php?toBankId=11&money=1000>的标签
2、B站有一段恶意js代码,实现了恶意功能,并且body有onload执行这个恶意代码
防御:
服务端的CSRF方式方法很多样,但总的思想都是一致的,就是在客户端页面增加伪随机数。
1、Cookie Hashing(所有表单都包含同一个伪随机值):因为攻击者不能获得第三方的Cookie(理论上)、
在表单里增加Hash值,以认证这确实是用户发送的请求,并用hidden_type,然后在服务器端进行Hash值验证
2、验证码:每次的用户提交都需要用户在表单中填写一个图片上的随机字符串
目录遍历
XSS
反射型XSS:<非持久化> 攻击者事先制作好攻击链接, 需要欺骗用户自己去点击链接才能触发XSS代码(服务器中没有这样的页面和内容)
存储型XSS:<持久化> 代码是存储在服务器中的,如在个人信息或发表文章等地方,加入代码,如果没有过滤或过滤不严,那么这些代码将储存到服务器中,每当有用户访问该页面的时候都会触发代码执行
DOM型XSS:基于文档对象模型Document Objeet Model,DOM)的一种漏洞。DOM是一个与平台、编程语言无关的接口,它允许程序或脚本动态地访问和更新文档内容、结构和样式,处理后的结果能够成为显示页面的一部分。DOM中有很多对象,其中一些是用户可以操纵的,如uRI ,location,refelTer等。客户端的脚本程序可以通过DOM动态地检查和修改页面内容,它不依赖于提交数据到服务器端,而从客户端获得DOM中的数据在本地执行,如果DOM中的数据没有经过严格确认,就会产生DOM XSS漏洞。
存储型XSS需要先把利用代码保存在比如数据库或文件中,当web程序读取利用代码时再输出在页面上执行利用代码。但存储型XSS不用考虑绕过浏览器的过滤问题,屏蔽性也要好很多。
防御
A.PHP直接输出html的,可以采用以下的方法进行过滤:
1.htmlspecialchars函数转义&"'<>``
2.htmlentities函数:对用户输入的<>`做了转义处理
3.HTMLPurifier.auto.php插件
4.RemoveXss函数
B.PHP输出到JS代码中,或者开发Json API的,则需要前端在JS中进行过滤:
1.尽量使用innerText(IE)和textContent(Firefox),也就是jQuery的text()来输出文本内容
2.必须要用innerHTML等等函数,则需要做类似php的htmlspecialchars的过滤
C.其它的通用的补充性防御手段
1.在输出html时,加上Content Security Policy的Http Header
(作用:可以防止页面被XSS攻击时,嵌入第三方的脚本文件等)
(缺陷:IE或低版本的浏览器可能不支持)
2.在设置Cookie时,加上HttpOnly参数
(作用:可以防止页面被XSS攻击时,Cookie信息被盗取,可兼容至IE6)
(缺陷:网站本身的JS代码也无法操作Cookie,而且作用有限,只能保证Cookie的安全)
3.在开发API时,检验请求的Referer参数
(作用:可以在一定程度上防止CSRF攻击)
(缺陷:IE或低版本的浏览器中,Referer参数可以被伪造)
SQL注入
在开发网站的时候,出于安全考虑,需要过滤从页面传递过来的字符。通常,用户可以通过以下接口调用数据库的内容:URL地址栏、登陆界面、留言板、搜索框等。这往往给骇客留下了可乘之机。
1:寻找到SQL注入的位置
2:判断服务器类型和后台数据库类型
3:针对不同的服务器和数据库特点进行SQL注入攻击
MS-SQL
与MySQL不一样的是,联合查询不能直接输入数字,占位符需要使用null
@@version,查询当前数据库版本
db_name(),查询当前数据库名称
user,查询当前用户
IS_SRVROLEMEMBER(),查询数据库权限。
常用权限:sysadmin、serveradmin、setupadmin、securityadmin、diskadmin、bulkadmin
Mysql
information_schema
使用order by来判断返回的条目的字段数量
使用union判断每个字段的显示位置
使用database() usr() 等函数获取有用的信息
user()是用来显示当前登陆的用户名与它对应的host,currrent_user()是用来显示当前登陆用户对应在user表中的哪一个
limit控制显示的条目
报错注入
extractvalue() updatexml()
floor() (floor()、rand())
SQLmap
-u 指定目标URL (可以是http协议也可以是https协议)
-d 连接数据库
–dbs 列出所有的数据库
–current-db 列出当前数据库
–tables 列出当前的表
–columns 列出当前的列
-D 选择使用哪个数据库
-T 选择使用哪个表
-C 选择使用哪个列
–dump 获取字段中的数据
–batch 自动选择yes
–smart 启发式快速判断,节约浪费时间
–forms 尝试使用post注入
-r 加载文件中的HTTP请求(本地保存的请求包txt文件)
-l 加载文件中的HTTP请求(本地保存的请求包日志文件)
-g 自动获取Google搜索的前一百个结果,对有GET参数的URL测试
-o 开启所有默认性能优化
–tamper 调用脚本进行注入
-v 指定sqlmap的回显等级
–delay 设置多久访问一次
–os-shell 获取主机shell,一般不太好用,因为没权限
-m 批量操作
-c 指定配置文件,会按照该配置文件执行动作
-data data指定的数据会当做post数据提交
-timeout 设定超时时间
-level 设置注入探测等级
–risk 风险等级
–identify-waf 检测防火墙类型
–param-del=”分割符” 设置参数的分割符
–skip-urlencode 不进行url编码
–keep-alive 设置持久连接,加快探测速度
–null-connection 检索没有body响应的内容,多用于盲注
–thread 最大为10 设置多线程
–tamper [“脚本名称”] (一些绕过过滤的脚本,比如用/**/替换空格)
PE
DOS头=MZ文件头+DOSstub(This program cannot be run in DOS mode)
PE头–可选文件头–定义了PE文件许多的关键信息,入内存镜像加载地址、程序入口点、节在文件和内存中的对齐粒度、程序在内存中的镜像大小、文件大小等等—输入表是记录输入函数相关信息的一张表,他记录了PE文件在运行过程中调用动态链接库的一些函数的名称和地址
节表
代码节
数据节
引入函数节
资源节等(如图标)
引出函数节(DLL文件中常见)
重定位节(DLL文件中常见)
burpsuit
spider intruder repeater
arp-scan
-l local
向局域网中所有可能的ip地址发出arp请求包,如果得到arp回应,就证明局域网中某台主机使用了该ip
nmap
直接加ip
-vv参数设置对结果的详细输出
-p(range)扫描的端口范围
-sP
–traceroute
-O(大写的o) 操作系统探查
-A 综合扫描
-sV 版本检测
-T [0-6]:设置定时模板(越高越快)
metasploit
msfconsole
search ***
use
show options
set ** **
shell
python -c ‘import pty;pty.spawn(“/bin/sh”)’模拟tty
show
show auxiliary显示Metasploit中的可用辅助模块列表,这些辅助模块包括scanner、dos、fuzzer等
show exploits 显示Metasploit中包含的所有可以利用的攻击类型列表。
show payloads 显示Metasploit中可以在不同平台中可以在远程主机执行的代码
show options 显示可利用模块exploit的设置、条件、描述等。在具体的模块中使用,后面use命令中会有实例。
show targets 显示可利用模块exploit支持的目标类型(操作系统、软件版本等)。
show advanced 显示可利用模块exploit高级信息,自定义利用程序时使用。
show encoders 显示可利用模块exploit的编码方式,在具体的模块中使用,后面set命令中会有实例。
任意文件读取
readfile()、file_get_contents()、fopen()如果参数没有经过校验或校验不合格,用户就可以控制变量读取任意文件。
任意文件下载
通过参数传递下载文件的位置,且对参数没有严格过滤,即可利用。与任意文件读取异曲同工。
也可以直接自己构造
MSSQL sql存储过程和CLR存储过程区别
CLR负责应用程序在整个执行期间的代码管理工作,比较典型的有:内存管理、线程管理、安全管理、远程管理、即使编译、代码强制安全类检查等
简单说,通过 CLR 能够在 SQLServer 中注册一套程序集,实现执行任意的 .NET 代码。并且由于CLR 注册 DLL 支持十六进制的方式,以这种方式不需要将 DLL 文件落地到目标机器上,实现了无文件落地,能够规避杀软。此外,在目标无法处出网的情况下,也能完成操作
sql存储过程: 直接同DB服务器更新交互
clr存储过程:需要采用ado.net的方式提交sql至db服务器
sql 存储过程:只需一个sql脚本就可以运行相关操作,就可以将数据返回给客户端
clr存储过程:需要通过sqlpipe对象将结果返回客户端
看过工具源码吗
看过githack和gakki改的gitextract
githack
解析.git/index文件,找到工程中所有的: ( 文件名,文件sha1 )
他用了一个别人写的praser来遍历index,具体方法有点不太记得了,基本上就是吧.git/index按他的字节格式一个一个的解析下来的,就一次读几个字节然后这几个字节应该是什么意思那样。当时我还想哪天去总结一下这个.git/index的格式来着,这两天一定。
去.git/objects/ 文件夹下下载对应的文件,用了create_unverified_context来实现ssl
zlib解压文件,按原始的目录结构写入源代码
gitextract
不仅解析了index,还解析了head等等好几项,基本上也是按照字节格式解析的。
断点原理
直接改写断点内存地址的第一个字节,替换为int3 (0xcc,软中断机制),并保存原始字节至OD维护的一张断点表处
反序列化
Java:自动调用readobject()方法
php:自动调用wakeup()方法
Python: 自动调用reduce__()方法
hook
两个队列:系统消息队列和应用消息队列
一个链:hook链
虚函数
C++基类里定义的方法,子类可以在自己那儿做出自己的实现
纯虚函数就是一定要自己实现
参考
https://mp.weixin.qq.com/s?__biz=MzAxNzYzMTU0Ng==&mid=2651289202&idx=1&sn=431ffd1fae4823366a50b68aed2838d4&chksm=80114627b766cf31f72018ef5f1fe29591e9f6f4bd72018e7aea849342ca6f0a271fb38465ae#rd
https://blog.csdn.net/m0_37552052/article/details/81453591
https://www.jianshu.com/p/4fcb4b411a66
https://cloud.tencent.com/developer/article/1736431
https://www.cnblogs.com/Rev-omi/p/14027780.html
https://www.jianshu.com/p/4f89f810d98e
https://blog.csdn.net/x_nirvana/article/details/61420056
https://www.cnblogs.com/makelu/p/11140824.html
https://www.cnblogs.com/tuyile006/p/10873975.html
https://blog.csdn.net/qq_41137136/article/details/86434796
https://blog.csdn.net/he_and/article/details/85224548
https://www.nowcoder.com/discuss/111857?type=0&order=0&pos=28&page=0
https://blog.csdn.net/qianqin_2014/article/details/51114105
 wechat
wechat alipay
alipay


